I think many of you will be surprised to learn some new, less known facts about the internet, the digital wonderland of the 21st century. We all know that the internet is huge, right? It would take us months or even years to Google search and find every single existing internet page. But did you know that all that we can find with Google, Bing, Yandex or any other »classic« search engine represents only a small fraction of what the web offers? The small fraction is only the tip of the iceberg — a traditional search engine sees about 0.03 percent of the information that is available[1]. So what is the rest of it actually? How can we find it? Where and why is it hidden? Just what is going on here?
Layers of the Internet
Many may consider the Internet and World Wide Web (web) to be synonymous, but they are not. Rather, the web is one portion of the Internet and a medium through which information may be accessed[2]. In conceptualizing the web, some may view it as consisting solely of the websites accessible through a traditional search engine such as Google. However, this content—known as the “Surface Web”—is only one portion of the web.
 There are many words to describe the deep web, including the invisible web, hidden web, and even Deepnet. The Deep Web refers to “a class of content on the Internet that, for various technical reasons, is not indexed by search engines,” and thus would not be accessible through a traditional search engine[3]. Why is that so? The best way to understand it is to look at the below diagram:
There are many words to describe the deep web, including the invisible web, hidden web, and even Deepnet. The Deep Web refers to “a class of content on the Internet that, for various technical reasons, is not indexed by search engines,” and thus would not be accessible through a traditional search engine[3]. Why is that so? The best way to understand it is to look at the below diagram:

Crawlers are excellent at crawling through static web pages, extracting information on those pages, and providing that information in the form of search results. However, there is valuable information tucked away below the surface of those search results – information buried inside online databases and dynamically generated pages that the search spiders are capable of crawling. Just a few examples of those tremendous databases include information like patents, census data, data collected by governmental institutions, climate data and academic databases filled with scientific papers overflowing with interesting and valuable information.
All of this does not include the deepest and darkest corner of the Internet where secretive onion websites exist, accessible only through special software, that we will take a closer look further below.
Information on the Deep Web includes content on private intranets (internal networks such as those at corporations, government agencies or universities), commercial databases like Lexis Nexis or Westlaw or sites that produce content via search queries or forms. Going even further into the web, the Dark Web is the segment of the Deep Web that has been intentionally hidden. The Dark Web is a general term that describes hidden Internet sites, that users cannot access without using the special software. While the content of these sites may be accessed, the publishers of these sites are concealed. Users access the Dark Web with the expectation of being able to share information and/or files with little risk of detection.
In 2005, the number of Internet users reached 1 billion worldwide. This number surpassed 2 billion in 2010 and crested over 3 billion in 2014. As of July 2016, more than 46% of the world population was connected to the Internet[4]. While data exist on the number of Internet users, data on the number of users accessing the various layers of the web and on the breadth of these layers are less clear.
Surface Web: The magnitude of the web is growing. According to one estimate, there were 330.6 million Internet top-level domain names registered globally during the first quarter of 2017[5]. This is a 12.87% increase from the number of domain names registered during the same period in 2016.[6] As of October 2017, there were estimated to be more than 1.270 billion websites[7]. Some other researchers have noted, however, that the assessment of internet is a difficult proposition since it is a distributed body and no complete index exists. Proposition numbers “only hint at the size of the Web,” as numbers of users and websites are constantly fluctuating[8].
Deep Web: The Deep Web, as noted, cannot be accessed by traditional search engines because the content in this layer of the web is not indexed. Information here is not “static and linked to other pages” as is information on the Surface Web, which you will be able to learn in next sections of this post. As researchers have noted, “it’s almost impossible to measure the size of the Deep Web. While some early estimates put the size of the Deep Web at 4,000–5,000 times larger than the surface web, the changing dynamic of how information is accessed and presented means that the Deep Web is growing exponentially and at arate that defies quantification.”[9]
Military Origins of the Deep Web
Like other areas of the Internet, the Deep Web began to grow with help from the U.S. military, which sought a way to communicate with intelligence assets and Americans stationed abroad without being detected. Paul Syverson, David Goldschlag and Michael Reed, mathematicians at the Naval Research Laboratory, began working on the concept of “onion routing” in 1995[10]. Their research soon developed into The Onion Router project, better known as Tor, in 1997 with funding from U.S. Department of Defense’s Defense Advanced Research Projects Agency (DARPA)[11].
All of this led up to the Free Haven Project, formed in 1999 as a research project by a group of students from the Massachusetts Institute of Technology. The MIT students, including Roger Dingledine and Nick Mathewson, worked with the Naval Research Laboratory mathematicians to develop the first instance of Tor that we are familiar with today[12].
The next generation of Tor was presented at the “Proceedings of the 13th USENIX Security Symposium” in 2004. As the paper explains, there were other anonymous systems too complicated to pursue as the process would involve the encryption of data followed by its decryption and then sending that message forward. This process would repeat each step of the way until it reached its destination, which meant a much longer lag in the communication. The U.S. Navy released the Tor code to the public in 2004, and in 2006 Dingledine, Mathewson and several others formed the Tor Project and released the service currently in use. In essence, it is all about the anonymity while accessing the digital reality.
Accessing the Dark Web
The Dark Web can be reached through decentralized, anonymized nodes on a number of networks including Tor or I2P (Invisible Internet Project).
While data on the magnitude of the Deep Web and Dark Web and how they relate to the Surface Web are not clear, data on Tor users do exist. According to metrics from the Tor Project, the mean number of daily Tor users in the United States across August and September of 2017 was 438,955 – or 18.31% of total mean daily Tor users[13]. The United States has the largest number of mean daily Tor users, followed by United Arab Emirates (13.55%), Russia (9.15%) and Germany (7.36%).
What is Tor and how does it work?
Tor “refers both to the software that you install on your computer to run Tor and the network of computers that manages Tor connections.”[14] Tor’s users connect to websites “through a series of virtual tunnels rather than making a direct connection, thus allowing both organizations and individuals to share information over public networks without compromising their privacy.”[15] Users route their web traffic through other users’ computers such that the traffic cannot be traced to the original user. Tor essentially establishes layers (like layers of an onion) and routes traffic through those layers to conceal users’ identities[16]. To get from layer to layer, Tor has established “relays” on computers around the world through which information passes[17]. Information is encrypted between relays, and “all Tor traffic passes through at least three relays before it reaches its destination.”[18] The final relay is called the “exit relay,” and the IP address of this relay is viewed as the source of the Tor traffic. When using Tor software, users’ IP addresses remain hidden. As such, it appears that the connection to any given website “is coming from the IP address of a Tor exit relay, which can be anywhere in the world.”[19]
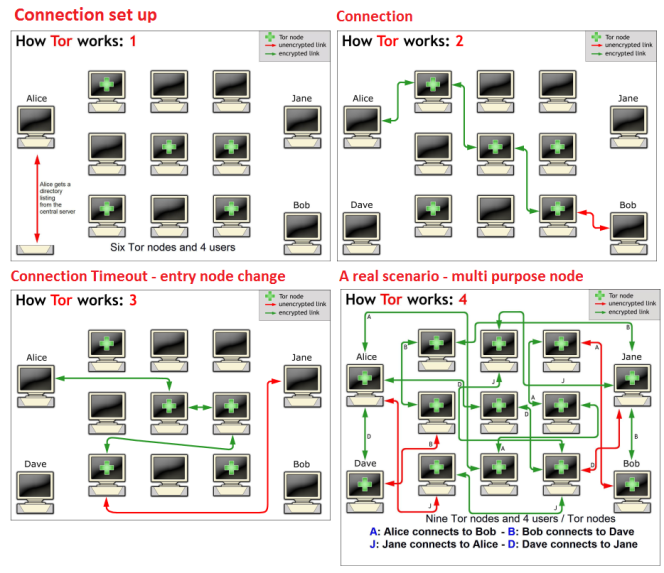
Navigating the Deep Web and Dark Web
As explained above, traditional search engines often use “web crawlers” to access websites on the Surface Web. This process of crawling searches the web and gathers websites that the search engines can then catalog and index[20]. Content on the Deep (and Dark) Web, however, may not be caught by web crawlers (and subsequently indexed by traditional search engines) for a number of reasons, including that it may be unstructured, unlinked, or temporary content. As such, there are different mechanisms for navigating the Deep Web than there are for the Surface Web.
Users often navigate Dark Web sites through directories such as the “Hidden Wiki,” which organizes sites by category, similar to Wikipedia. In addition to the wikis, individuals can also search the Dark Web with search engines. These search engines may be broad, searching across the Deep Web, or they may be more specific. For instance, Ahmia, an example of a broader search engine, is one “that indexes, searches and catalogs content published on Tor Hidden Services” [21]. In contrast, Grams is a more specific search engine “patterned after Google” where users can find illicit drugs, guns, counterfeit money, and other contraband[22].
When using Tor, website URLs change formats. Instead of websites ending in .com, .org, .net, etc., domains usually end with an “onion” suffix, identifying a “hidden service.”[23] Notably, when searching the web using Tor, an onion icon displays in the Tor browser.
Tor is notoriously slow, and this has been cited as one drawback to using the service. This is because all Tor traffic is routed through at least three relays, and there can be delays anywhere along its path. In addition, speed is reduced when more users are simultaneously on the Tor network.[24] On the other hand, increasing the number of users who agree to use their computers as relays can increase the speed on Tor.
Tor and similar networks are not the only means to reach hidden content on the web. Other developers have created tools—such as Tor2web—that may allow individuals access to Torhosted content without downloading and installing the Tor software[25]. Using bridges such as Tor2web, however, does not provide users with the same anonymity that Tor offers. As such, if users of Tor2web or other bridges access sites containing illegal content—for instance, those that host child pornography—they could more easily be detected by law enforcement than individuals who use anonymizing software such as Tor.
Illegal Activity and the Dark Web
Just as nefarious activity can occur through the Surface Web, it can also occur on the Deep Web and Dark Web. A range of malicious actors leverage cyberspace, from criminals to state-sponsored spies. The web can serve as a forum for conversation, coordination, and action. Specifically, they may rely upon the Dark Web to help carry out their activities with reduced risk of detection. While this section focuses on criminals operating in cyberspace, the issues raised are certainly applicable to other categories of malicious actors.
For instance, criminals can easily leverage the Internet to carry out traditional crimes such as distributing illicit drugs and sex trafficking. In addition, they exploit the digital world to facilitate crimes that are often technology driven, including identity theft, payment card fraud, and intellectual property theft. The FBI considers high-tech crimes to be among the most significant crimes confronting the United States.
The Dark Web has been cited as facilitating a wide variety of crimes. Illicit goods such as drugs, weapons, exotic animals, and stolen goods and information are all sold for profit. There are gambling sites, thieves and assassins for hire, and troves of child pornography.[26] Data on the prevalence of these Dark Web sites, however, are lacking. Tor estimates that only about 1.5% of Tor users visit hidden services/Dark Web pages[27]. The actual percentage of these that serve a particular illicit market at any one time is unclear, and it is even less clear how much Tor traffic is going to any given site.
One study from the University of Portsmouth examined Tor traffic to hidden services. Researchers “ran 40 ‘relay’ computers in the Tor network … which allowed them to assemble an unprecedented collection of data about the total number of Tor hidden services online—about 45,000 at any given time—and how much traffic flowed to them.”[28] While about 2% of the Tor hidden service websites identified were sites that researchers deemed related to child abuse, 83% of the visits to hidden services sites were to these child abuse sites—“just a small number of pedophilia sites account for the majority of Dark Web http traffic.”[29]As has been noted, however, there are a number of variables that may have influenced the results.
Another study from King’s College London scanned hidden services on the Tor network. Starting with two popular Dark Web search engines, Ahmia and Onion City, they used a web crawler to identify 5,205 live websites[30]. Of these 5,205 websites, researchers identified content on about half (2,723) and classified them by the nature of the content. Researchers determined that 1,547 sites contained illicit content. This is a sample of websites on hidden services in Tor; the researchers’ crawler accessed about 300,000 websites (including 205,000 unique pages) on the network of Tor hidden services. Of note, in 2015 Tor estimated that there were about 30,000 hidden services that “announce themselves to the Tor network every day.”[31] Further, Tor estimated that “hidden service traffic is about 3.4% of total Tor traffic.”[32] More recent data from March 2016 to March 2017 indicate that there were generally between 50,000 and 60,000 hidden services, or unique .onion addresses, daily (with more data available at this link).
The following infographics is a nice visual summary of everything said so far. While you will be able to notice slightly different numbers or statistics in relation to the Deep Web, it can be understood as an attempt at correct assessment, which is impossible to be hundred percent accurate for the reasons already explained in the above text. Also note that the authors briefly mention Edward Snowden, who was outed by Miles Mathis as one of the “guys in some faction of Intelligence”. Snowden is mentioned as some kind of a reference or positively accepted example of using the Dark Web for his alleged hideous whistleblowing posts.

[1]Michael K. Bergman, https://quod.lib.umich.edu/j/jep/3336451.0007.104?view=text;rgn=main
[2] https://www.cigionline.org/sites/default/files/gcig_paper_no6.pdf , p.1
[3] https://www.cigionline.org/sites/default/files/gcig_paper_no6.pdf , p.1
[4] http://www.internetlivestats.com/internet-users/
[5] https://www.verisign.com/assets/domain-name-report-Q12017.pdf , p.2
[6] https://www.verisign.com/assets/domain-name-report-july2016.pdf, p2
[7] http://www.internetlivestats.com/
[8] You may notice that by visiting the above link, where the internet live statistic is presented. What is meant by asking how large the Internet is also defines how we answer the question. Do we mean how many people use the Internet? How many websites are on the Internet? How many bytes of data are contained on the Internet? How many distinct servers operate on the Internet? How much traffic runs through the Internet per second? All of these different metrics could conceivably be used to address the sheer size of the Internet, but all are very different.
[9] https://brightplanet.com/2012/06/deep-web-a-primer/
[10] You can find a research paper by the named individuals describing an architecture of Onion Routing here. Using the words of Tor’s fathers, »It provides real-time, bi-directional, anonymous communication for any protocol that can be adapted to use a proxy service. Specifically, the architecture provides for bi-directional communication even though no-one but the initiator’s proxy server knows anything but previous and next hops in the communication chain. This implies that neither the respondent nor his proxy server nor any external observer need to know the identity of the initiator or his proxy server.«
[12] http://www2.technologyreview.com/tr35/profile.aspx?TRID=583
[14] https://gizmodo.com/tor-the-anonymous-internet-and-if-its-right-for-you-1222400823
[16] https://gizmodo.com/tor-the-anonymous-internet-and-if-its-right-for-you-1222400823
[17] Individuals can volunteer their computers to be “relays” through which information may pass.
[18] https://www.eff.org/pages/what-tor-relay
[19] Ibid. According to the Electronic Frontier Foundation, “an exit relay is the final relay that Tor traffic passes through before it reaches its destination. Exit relays advertise their presence to the entire Tor network, so they can be used by any Tor users. Because Tor traffic exits through these relays, the IP address of the exit relay is interpreted as the source of the traffic.”
[20] http://www.google.com/insidesearch/howsearchworks/crawling-indexing.html
[21] Ahmia is available at https://ahmia.fi/search/
[22] https://www.wired.com/2014/04/grams-search-engine-dark-web/
[23] http://resources.infosecinstitute.com/diving-in-the-deepweb/ ; These .onion addresses “are 16-character alpha-semi-numeric hashes which are automatically generated based on a public key created when the hidden service is configured.”
[24] https://gizmodo.com/tor-the-anonymous-internet-and-if-its-right-for-you-1222400823
[25] https://www.wired.com/2008/12/tor-anonymized/
[26] https://www.wired.com/2014/12/80-percent-dark-web-visits-relate-pedophilia-study-finds/
[27] https://www.wired.com/2015/01/department-justice-80-percent-tor-traffic-child-porn/
[28] https://www.wired.com/2014/12/80-percent-dark-web-visits-relate-pedophilia-study-finds/
[29] Ibid
[30] http://www.tandfonline.com/doi/full/10.1080/00396338.2016.1142085?scroll=top&needAccess=true
[31] https://blog.torproject.org/some-statistics-about-onions
[32] Ibid

Very informative post, Vex. I learned a lot!
LikeLike
Very good stuff, Vex. I will do a promote (if that helps) in a couple of days after Tyrone’s post has been in spotlight. This is a unique post, loaded with detail.
LikeLike
Just filling in box to be notified of new posts.
LikeLike
Vexman,
Well done and very informative. Thanks for taking the time to post this. I first heard about this topic last year when I watched a documentary on Amazon Video. For those who are not aware there is a documentary on Amazon called “Deep Web” that goes into more detail about a gifted college student who gets caught up in all this hidden web stuff and then is arrested by the govt. It follows his mother through this whole ordeal in trying to free her son. Worth a look if you have time to spare.
LikeLike
I used Tor for several years in China, before the Great Fire Wall learnt how to block it (by simply blocking, one by one, each node: they have a large staff). After that I lived without Youtube.
Do you think it should be a concern that it was initially developed
I know it’s open source now, and has been for many years, but I not sure that I trust that crew.
LikeLike
Should it be a concern? US Army “invented” the whole internet and hidden some part of it, using it for dubious purposes, that’s what I think of it. Roger Dingledine and Nick Mathewson are co-founders of Tor and still very active within its development. Open source would be a perfect disguise for doing any dishonest modifications to i.e. Tor while hiding behind anonymity, right? Anyway, I’m suspicious about Dingledine, his CV says that his “other previous employers include the MIT network security team, a summer internship at the National Security Agency“, as this would possibly imply he got recruited there. So, to answer about your question of concern, I wouldn’t bet there is any true anonymity possible while one is online. That’s how I would do it, if I was US Army inventing the digital web.
LikeLiked by 1 person
They didn’t “hide” anything, nor were they using it for “dubious purposes”, and that this is the first conclusion you would jump to can only be interpreted as simple-mindedness at best. TOR was initially invented for secure communication, which any military would desire. Furthermore, open-source would be the opposite of a “disguise”, since it means anyone can see and judge for themselves exactly how the system is built, and every modification to the project can be viewed by the public. Your comment about dishonest modifications makes no sense whatsoever, if you realize that they never had to make the entire project open-source in the first place. Yes, they needed a lot of people to access TOR because the more people there are on the network, the more anonymous it gets. But that didn’t require them to make the project open-source.
LikeLike
You assume a lot and offer only your opinion to support it. Hmm, it sounds familiar. If you read carefully enough, you may notice I commented as “they’ve hidden some part of it”. That would be any army’s desire – to have a private “channel” for their own communication, possibly accessible only via a special tool / software / path. Enter Dark Web with TOR . So, looking at Dark Web as some hidden part of the internet as a whole, my statement makes more sense than your own. Simple-mindedness looks like your own attribute in this case, doesn’t it?
The case of open source programming is much more complex then you assume or suggest. Do you know how many program lines does TOR have? Do you know each single line and its functions? Are you able to test all combinations of these program lines and what they can do to with your system? How do you apply a testing process of a constantly changing piece of software? How can you guarantee any downloaded TOR is exactly the same, with no backdoors integrated? Do you have 100% control over DL servers hosting TOR for people to access and install on their machines? These are just initial and most obvious issues about any open source software, so I’d be very careful with trusting any piece of open source SW by default. Bear in mind we’re talking about extremely serious content going through TOR which needs secured lines of communications. So to expect complexity and extreme secure precautions is certainly more logical then expecting open-sourced program code, isn’t it? After all, we’re talking about army’s secure communications here. Right? It again appears to me that your suggestion makes less sense then my own.
By making TOR project open-source by appearance, you certainly get this feeling of alleged transparency with the users. I assume majority would be thinking just like you – trusting their own assumption about transparency of open-source approach. The truth is that this majority of TOR users – in reality – has absolutely no knowledge about programming, has never tested any important syntax of the program code in their entire life, has no knowledge about OS backdoors, has no possibilities to perform any testing or report the registered abuse, etc… You put way too much trust in some army’s product, just as anyone else who might believe army can be trusted in this aspect. I think it’s probably just the opposite – army’s version of TOR is nothing alike public TOR and I further assume army uses regular TOR users’ computers for their own anonymity and other purposes. That certainly sounds much more plausible “secure army’s communication” plan than what you suggest with your idea of open source. To me, the suggestion of open-source program used for secure army communication purposes, sounds as ultimate naivety or utter misdirection.
LikeLike
I viewed the dark web and it seemed kinda outdated and fake. Most of the drugs and firearms were overseas. Some of the so called gruesome photos were taken from the Faces of Death series. It also gave a vibe that if you did try to contact a hit man or anyone for illegal purposes, you would be talking to federal agents. Dark Web….I’m not impressed.
LikeLike
This is a very good point. Miles has shown the value to be gained from simply paying attention to details on Wikipedia. There is a lot of noise on the internet, and the skill is to find the signal. Conceptually, the iceberg meme just further increases the difficulty, decreasing the signal to noise ratio even further.
LikeLike
Hi Greg. Can you be more specific about your experience? You said you’ve viewed the dark web, but that would be like saying you’ve viewed the internet which contains billions of web pages. To what server did you connect while diving into the Dark web? Was is a portal, like the infamous Silk Road? Or some even more obscure site? In my experience, it completely depends on where you land with your hit, some sites/servers are truly only old-fashioned list of items (as when we used to type “dir /” in DOS, where the machine would simply list content of the directory in reply).
I don’t understand completely, what vibe is talking to federal agents about any hitman jobs. Its probably lack of my experience, but can you elaborate on this further? I’d really like to know if there is anything more substantial about that other than your feeling. Maybe I read your comment wrong, but I got a feeling your are dismissing the whole subject with a wave of your hand, based only on your feeling.
LikeLike